Specs in Git. Signed releases. Test harnesses for JUnit, pytest,
and Vitest. No new SaaS, no new auth — promptLM lives in the Git
infra your team already trusts.
Spec to release to replay — the prompt lifecycle, one tool deep.
PROMPTS AS SPEC
Define a prompt. Version it. Release it.
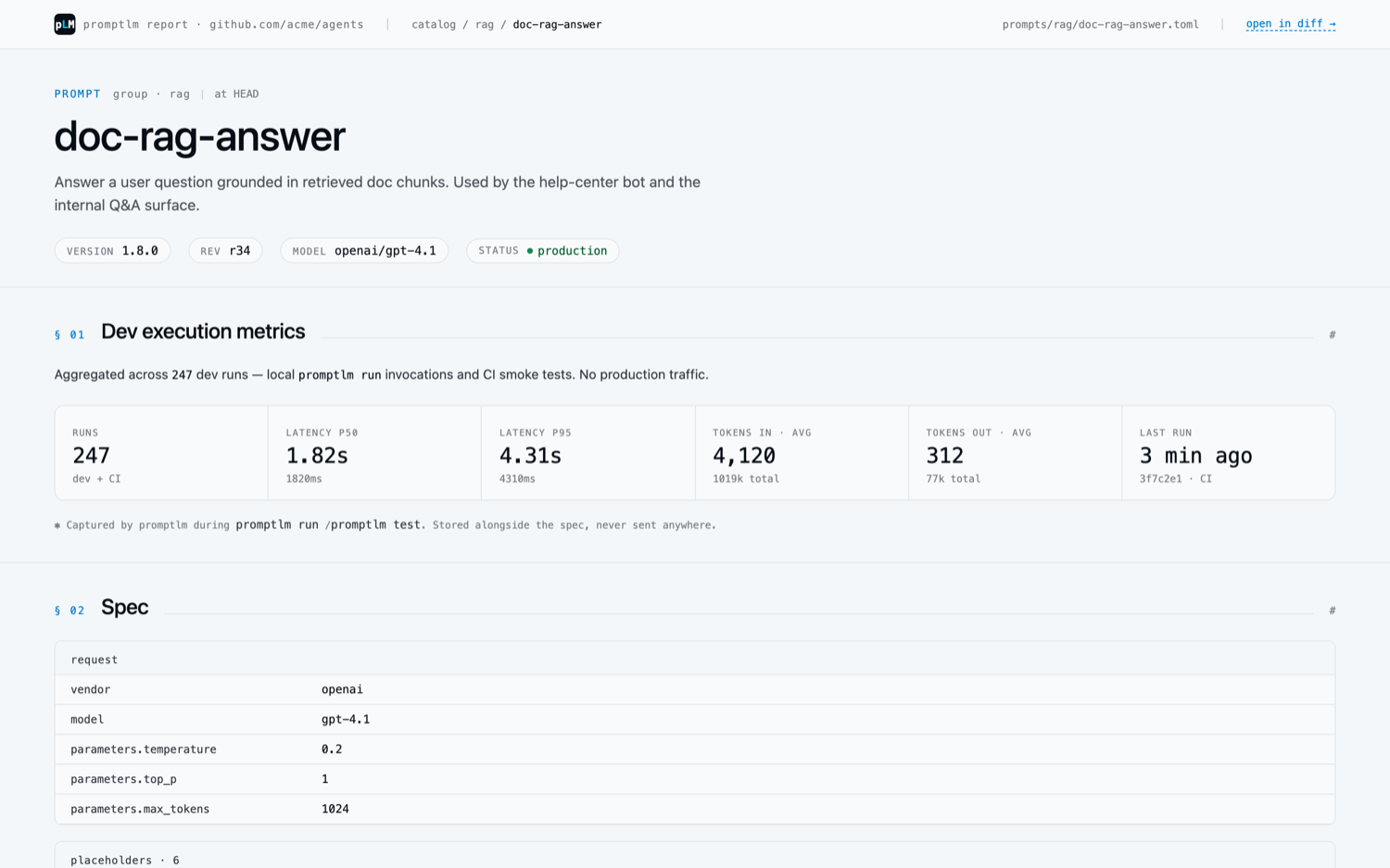
Every prompt is a spec file — vendor, model, parameters, messages.
Versioned in Git. Released as a signed JAR your app pins.
# promptlm.yamlid: customer_support
group: support
version: 1.0.0request:
vendor: openai
model: gpt-4o
parameters: { temperature: 0.6, maxTokens: 256 }
messages:
- role: system
content: You are a support assistant.
- role: user
content: "Summarize: {{ticket}}"
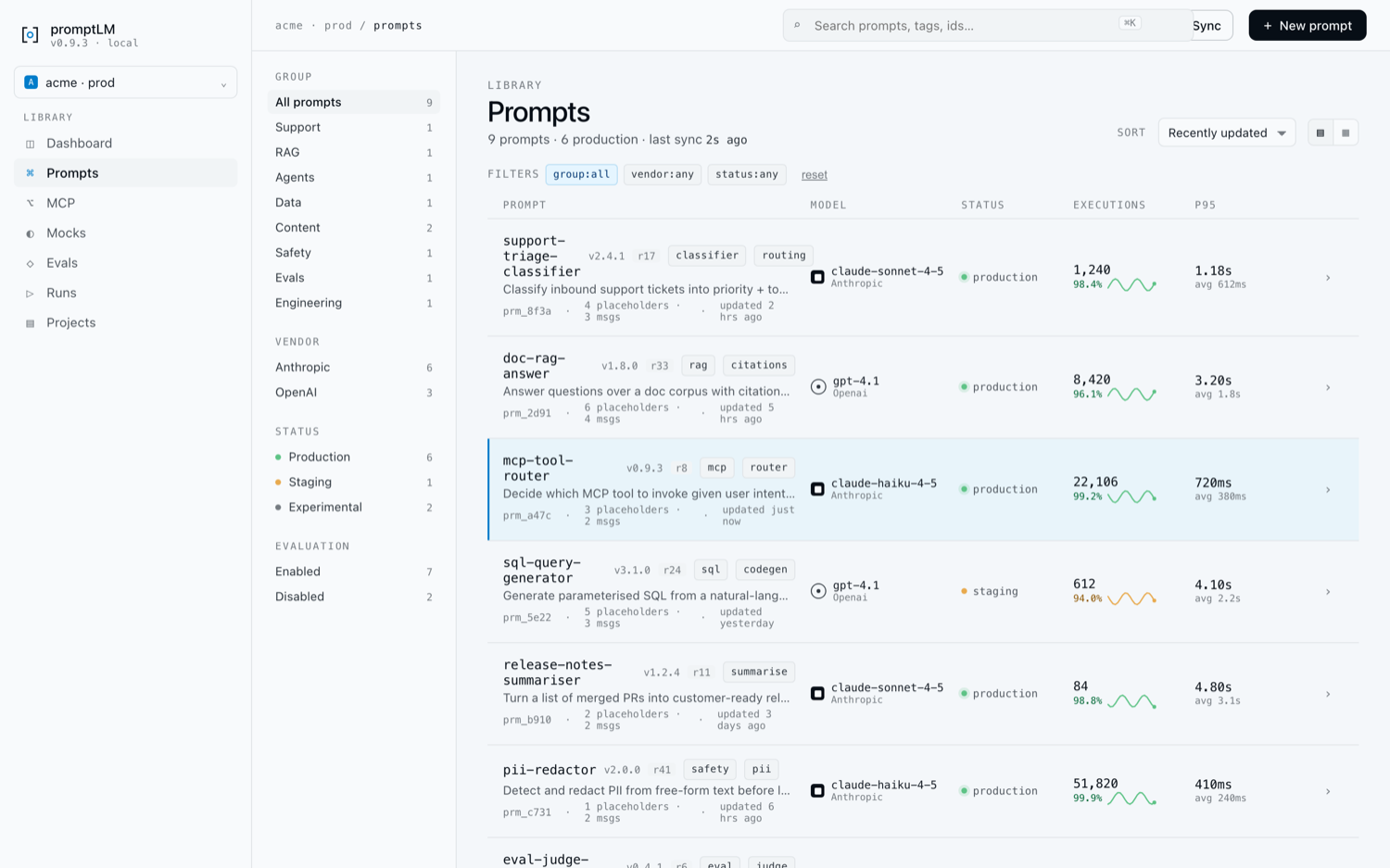
STUDIO CATALOG
Every prompt. Every release. One catalog.
Browse, search, and filter the inventory. See status, executions,
and latency at a glance. Syncs from Git on push.
IN YOUR APP
Pin a version. Load it. Ship it.
Released prompts ship as a JAR your app depends on. Load by id,
fill placeholders, send. Vendor, model, and parameters travel with
the spec — your code never drifts from the prompt.
// SupportService.java
Prompt prompt = PromptLoader.load("customer_support"); // pinned v1.0.0 in pom.xml
String filled = prompt.fill(Map.of("ticket", ticket));
// vendor, model, parameters come from the spec — not your code
String reply = llm.send(filled, prompt.model(), prompt.parameters());
TEST SUPPORT
Test against recorded responses.
Each released prompt ships with golden responses captured during
dev. Your tests replay them locally via WireMock — no real LLM
calls, no tokens billed, deterministic in CI.
Golden responses bundled with the prompt JAR
WireMock stubs auto-generated — no manual fixtures
@InjectResponse for equality assertions
Zero tokens. Zero flake. Same bytes, every run.
// SupportServiceTest.java@EnablePromptWireMock// boots WireMock on a local port,class SupportServiceTest { // pre-stubbed from your prompt repo@Testvoid summarizesTicket(@InjectResponse(id = "customer_support") String recorded) {
String reply = supportService.summarize(ticket); // your prod code POSTs to the LLM// The LLM URL points at WireMock, so the recorded reply is returned.// No real model call, no tokens billed, deterministic across runs.
assertThat(reply).isEqualTo(recorded);
}
}
# test_support_service.pyfrom promptlm.testing import enable_prompt_mock, inject_response
@enable_prompt_mock# boots a mock LLM on a local port,@inject_response("customer_support") # pre-stubbed from your prompt repodef test_summarizes_ticket(recorded: str):
reply = support_service.summarize(ticket) # your prod code POSTs to the LLM# The LLM URL points at the mock, so the recorded reply is returned.# No real model call, no tokens billed, deterministic across runs.assert reply == recorded
// supportService.test.tsimport { enablePromptMock, injectResponse } from'@promptlm/testing';
enablePromptMock(); // boots a mock LLM on a local port,
test('summarizes ticket', () => { // pre-stubbed from your prompt repoconst recorded = injectResponse('customer_support');
const reply = supportService.summarize(ticket); // your prod code POSTs to the LLM// The LLM URL points at the mock, so the recorded reply is returned.// No real model call, no tokens billed, deterministic across runs.
expect(reply).toBe(recorded);
});
COMING SOONROADMAP
MCP record/replay test harness.
Capture every tool call against your real MCP servers, freeze the
bytes, and replay them deterministically in CI. No flaky network,
no vendor rate limits, no surprise charges. Same story as
prompt replay — extended to the tools your agent actually uses.